If you've been keeping up with this blog then you understand a bit about IOMMU groups and device isolation. In my howto series I describe the limitations of the Xeon E3 processor that I use in my example system and recommend Xeon E5 or higher processors to provide the best case device isolation for those looking to build a system. Well, thanks to the vfio-users mailing list, it has come to my attention that there are in fact Core i7 processors with PCIe Access Control Services (ACS) support on the processor root ports.
Intel lists these processors as High End Desktop Processors, they include Socket 2011-v3 Haswell E processors, Socket 2011 Ivy Bridge E processors, and Socket 2011 Sandy Bridge E processors. The linked datasheets for each family clearly lists ACS register capabilities. Current listings for these processors include:
Haswell-E (LGA2011-v3)
i7-5960X (8-core, 3/3.5GHz)
i7-5930K (6-core, 3.2/3.8GHz)
i7-5820K (6-core, 3.3/3.6GHz)
Ivy Bridge-E (LGA2011)
i7-4960X (6-core, 3.6/4GHz)
i7-4930K (6-core, 3.4/3.6GHz)
i7-4820K (4-core, 3.7/3.9GHz)
Sandy Bridge-E (LGA2011)
i7-3960X (6-core, 3.3/3.9GHz)
i7-3970X (6-core, 3.5/4GHz)
i7-3930K (6-core, 3.2/3.8GHz)
i7-3820 (4-core, 3.6/3.8GHz)
These also appear to be the only Intel Core processors compatible with Socket 2011 and 2011-v3 found on X79 and X99 motherboards, so basing your platform around these chipsets will hopefully lead to success. My recommendation is based only on published specs, not first hand experience though, so your mileage may vary.
Unfortunately there are not yet any Skylake based "High End Desktop Processors" and from what we've seen on the mailing list, Skylake does not implement ACS on processor root ports, nor do we have quirks to enable isolation on the Z170 PCH root ports (which include a read-only ACS capability, effectively confirming lack of isolation), and integrated I/O devices on the motherboard exhibit poor grouping with system management components (aside from the onboard I219 LOM, which we do have quirked). This makes the currently available Skylake platforms a really bad choice for doing device assignment.
Based on this new data, I'll revise my recommendation for Intel platforms to include Xeon E5 and higher processors or Core i7 High End Desktop Processors (as listed by Intel). Of course there are combinations where regular Core i5, i7 and Xeon E3 processors will work well, we simply need to be aware of their limitations and factor that into our system design.
EDIT (Oct 30 04:18 UTC 2015): A more subtle feature also found in these E series processors is support for IOMMU super pages. The datasheets for the E5 Xeons and these High End Desktop Processors indicate support for 2MB and 1GB IOMMU pages while the standard Core i5 and i7 only support 4KB pages. This means less space wasted for the IOMMU page tables, more efficient table walks by the hardware, and less thrashing of the I/O TLB under I/O load resulting in I/O stalls. Will you notice it? Maybe. VFIO will take advantage of IOMMU super pages any time we find a sufficiently sized range of contiguous pages. To help insure this happens, make use of hugepages in the VM.
EDIT (Oct 15 18:20 UTC 2016): Intel Broadwell-E processors have been out for some time and as we'd expect, the datasheets do indicate that ACS is supported. So add to the list above:
Broadwell-E (LGA2011-v3)
i7-6950X (10-core, 3.0/3.5GHz)
i7-6900K (8-core, 3.2/3.7GHz)
i7-6850K (6-core, 3.6/3.8GHz)
i7-6800K (6-core, 3.4/3.6GHz)
Friday, October 23, 2015
Wednesday, September 2, 2015
libvirt 1.2.19 - session mode device assignment
Just a quick note to point out a feature, actually bug fix, in the new libvirt 1.2.19 release:
hostdev: skip ACS check when using VFIO for device assignment (Laine Stump)
Why is this noteworthy? Well, that ACS checking required access to PCI config space beyond the standard header, which is privileged. That means that session (ie. user) mode libvirt couldn't do it and failed trying to support <hostdev> entries. Now that libvirt recognizes that vfio enforces device isolation and a userspace ACS test is unnecessary, session mode libvirt can support device assignment! Thanks Laine!
Note that a user still can't just pluck a device from the host and start using it, that's still privileged. There's also the problem that a VM making use of device assignment needs to lock all of the VM memory into RAM, which is typically quite a lot more than the standard user locked memory limit of 64kB. But these can be resolved by enabling the (trusted) user to lock memory sufficient for their VM and preparing the device for the user. The keys to doing this are:
hostdev: skip ACS check when using VFIO for device assignment (Laine Stump)
Why is this noteworthy? Well, that ACS checking required access to PCI config space beyond the standard header, which is privileged. That means that session (ie. user) mode libvirt couldn't do it and failed trying to support <hostdev> entries. Now that libvirt recognizes that vfio enforces device isolation and a userspace ACS test is unnecessary, session mode libvirt can support device assignment! Thanks Laine!
Note that a user still can't just pluck a device from the host and start using it, that's still privileged. There's also the problem that a VM making use of device assignment needs to lock all of the VM memory into RAM, which is typically quite a lot more than the standard user locked memory limit of 64kB. But these can be resolved by enabling the (trusted) user to lock memory sufficient for their VM and preparing the device for the user. The keys to doing this are:
- Use /etc/security/limits.conf to increase memlock for the desired user
- Pre-bind the desired device to vfio-pci, either by the various mechanisms provided in other posts or simply using virsh nodedev-detach.
- Change the ownership of the vfio group to that of the (trusted) user. To determine the group, follow the links in sysfs or use virsh nodedev-dumpxml, for example:
$ virsh nodedev-dumpxml pci_0000_00_19_0
<device>
<name>pci_0000_00_19_0</name>
<path>/sys/devices/pci0000:00/0000:00:19.0</path>
<parent>computer</parent>
<driver>
<name>e1000e</name>
</driver>
<capability type='pci'>
<domain>0</domain>
<bus>0</bus>
<slot>25</slot>
<function>0</function>
<product id='0x1502'>82579LM Gigabit Network Connection</product>
<vendor id='0x8086'>Intel Corporation</vendor>
<iommuGroup number='4'>
<address domain='0x0000' bus='0x00' slot='0x19' function='0x0'/>
</iommuGroup>
</capability>
</device>
The iommuGroup sections tells us that this is group number 4, so permissions need to be set on /dev/vfio/4. As always, also note the set of devices within this group and ensure that all endpoints listed are either bound to vfio-pci or pci-stub, the former will allow the user access to the device, the latter will allow the group to be usable without explicitly allowing the user access.
Enjoy!
Tuesday, August 11, 2015
vfio-users mailing list
The Arch Linux VGA thread was recently closed leaving a number of users looking for a place to continue the conversation. To facilitate that, I've created a vfio-users mailing list for discussion of all topics related to vfio. That includes QEMU device assignment use cases, such as VGA/GPU, as well as userspace drivers. Though hosted by Red Hat, this is a distribution independent forum intended to further vfio and its use cases as a technology. Please be respectful of each other and keep topics relevant to the forum. Sign up here
Tuesday, May 5, 2015
VFIO GPU How To series, part 5 - A VGA-mode, SeaBIOS VM
For this example I'm show how to setup a VGA-mode VM using a Windows 7 guest and SeaBIOS. In this case we are not dependent on the guest or the graphics card supporting UEFI, but with Intel host graphics, we do need to work around the Linux i915 driver's broken participation in VGA arbitration. If you intend to use IGD for the host, the typical solution for this is to apply the i915 patch to the host kernel and use the enable_hd_vgaarb=1 option for the i915 driver to make it correctly participate in VGA arbitration. The side-effect of doing this is the loss of DRI support in the host Xorg server.
However, since this is just a demo, I'm going to be lazy and modify my script from part 4 of this series to comment out the test for boot_vga being non-zero such that vfio-pci will be set as the driver override for all VGA devices in the system. This limits my system to text-mode on the primary head for this example. For a long term solution, I would either be looking for a UEFI/OVMF setup as outlined in part 4, or disabling IGD and using discrete graphics for the host. Continuing to patch kernels for i915 VGA arbitration support is of course an option too, if you enjoy that sort of thing. If you're not using IGD on the host, or like my example, avoiding the i915 driver, you should be ok.
Windows 7 VM installation is largely the same as Windows 8 installation in part 4. The difference is that we're not going to modify the VM firmware to use UEFI, we'll leave that set to BIOS. The other difference is that BIOS won't drop to a shell and allow us to manually boot from the install CD after we've broken the boot order by adding the virtio drivers. My brute force solution to this is to attempt to boot the VM, it will error and say no OS found, force the VM off, then modify the boot options to push the Windows CDROM above the virtio disk and start the VM again. I expect that you could also enable the boot menu on the first pass and try to catch the F12 prompt to select the correct boot device.
After installation, update, and installing TightVNC, as in part 4, shut down the VM, prune and tune the VM using virsh edit, just as we did in the previous setup. If you're using Nvidia also add the KVM hidden section to features, removing the Hyper-V section and disable the Hyper-V clock source. Also return to virt-manager and add the GPU and audio function to the VM. All of this is documented in part 4.
Before you start the VM with the GPU, we first need to make a wrapper script around our qemu-kvm binary to insert the x-vga=on option. To do this, create a file named /usr/libexec/qemu-kvm.vga with the following:
#!/bin/sh
exec /usr/libexec/qemu-kvm \
`echo "\$@" | \
sed 's|01:00.0|01:00.0,x-vga=on|g' | \
sed 's|02:00.0|02:00.0,x-vga=on|g'`
We'll use this as the executable libvirt uses in place of qemu-kvm directly. Any time the qemu-kvm command line contains 01:00.0 or 02:00.0, which are the PCI addresses of the graphics cards in my system, we'll add the option ",x-vga=on". This makes it transparent to libvirt that this is happening. Be sure to chmod 755 the file before proceeding.
If your system is using selinux, libvirt will get an audit error trying to execute this script, so we'll need to add a new selinux module to allow for this. Red Hat documentation here provides instructions for doing this. In summary:
Set the selinux permissions for the file:
# restorecon /usr/libexec/qemu-kvm.vga
Create an selinux module
# cat > qemukvmvga.te << EOF
policy_module(qemukvmvga, 1.0)
gen_require(\`
attribute virt_domain;
type qemu_exec_t;
')
can_exec(virt_domain, qemu_exec_t)
EOF
Build the selinux module
# make -f /usr/share/selinux/devel/Makefile
Install selinux module
# semodule -i qemukvmvga.pp
With selinux happy, we next need to run virsh edit on the domain again. Find the <emulator> tag and update the executable to point to our new script. Save and exit the configuration and you should now be able to start the VM from virt-manager with VGA-mode enabled. The same driver installation guidelines from part 4 apply for the GeForce/Catalyst drivers. Enjoy.
VFIO GPU How To series, part 4 - Our first VM
At this point in the series you should have a system capable of device assignment and properly configured to sequester at least the GPU from the host for assignment to a guest. You should already have your distribution packages installed for QEMU/KVM and libvirt, including virt-manager. In this article we'll cover installation and configuration of the guest for UEFI capable graphics card and UEFI capable guest. This is the configuration I'd recommend for most users as it's the most directly supported. Unless you absolutely cannot upgrade your graphics card or guest OS, this is the configuration most users should aim for.

My ISOs are stored on an NFS mount that I already configured, so I use the Local install media option. Clicking Forward brings us to the next dialog where I select my ISO image location and select the OS type and version:

This allows libvirt to pre-configure some defaults for the VM, some of which we'll change as we move along. Stepping forward again, we can configure the VM RAM size and number of vCPUS:

For my example VM I'll use the defaults. These can be changed later if desired. Next we need to create a disk for the new VM:










I'll be using the hardware configuration discussed in part 1 of this series along with Windows 8.1 (64 bit) as my guest operating system. Both my EVGA GTX 750 and Radeon HD8570 OEM support UEFI as determined here, and I'll cover the details unique to each. Each GPU is connected via HDMI to a small LED TV, which will also be my primary target for audio output. Perhaps we'll discuss in future articles the modifications necessary for host-based audio.
The first step is to start virt-manager, which you should be able to do from your host desktop. If your host doesn't have a desktop, virt-manager can connect remotely over ssh. We'll mostly be using virt-manager for installation and setup, and maybe future maintenance. After installation you can set the VM to auto start or start and stop it with the command line virsh tools. If you've never run virt-manager before, you probably want to start with configuring your storage and networking Either by Edit->Connection Details or right click on the connection and selecting Details in the drop-down. I have a mounted filesystem setup to store all of my VM images and NFS mounts for ISO storage. You can also configure full physical devices, volume groups, iSCSI, etc. Volume groups are another favorite of mine to be able to have full flexibility and performance. libvirt's default will be to create VM images in /var/lib/libvirt/images, so it's also fine if you simply want to mount space there.
Next you'll want to click over to the Network Interfaces tab. If you want the host and guest to be able to communicate over the network, which is necessary if you want to use tools like Synergy to share a mouse and keyboard, then you'll want to create a bridge device and add your primary host network to the bridge. If host-guest communication is not important for you, you can simply use a macvtap connection when configuring the VM networking. This may be perfectly acceptable if you're creating a multi-seat system and providing mouse and keyboard via some other means (USB passthrough for host controller assignment).
Now we can create our new VM:

My ISOs are stored on an NFS mount that I already configured, so I use the Local install media option. Clicking Forward brings us to the next dialog where I select my ISO image location and select the OS type and version:

This allows libvirt to pre-configure some defaults for the VM, some of which we'll change as we move along. Stepping forward again, we can configure the VM RAM size and number of vCPUS:

For my example VM I'll use the defaults. These can be changed later if desired. Next we need to create a disk for the new VM:

The first radio button will create the disk with an automatic name in the default storage location, the second radio button allows you to name the image and specify the type. Generally I therefore always select the second option. For my VM, I've created a disk with these parameters:

In this case I've created a 50GB, sparse, raw image file. Obviously you'll need to size the disk image based on your needs. 50GB certainly doesn't leave much room for games. You can also choose whether to allocate the entire image now or let it fault in on demand. There's a little extra overhead in using a sparse image, so if space saving isn't a concern, allocate the entire disk. I would also generally only recommend a qcow format if you're looking for the space saving or snap-shotting features provided by qcow. Otherwise raw provide better performance for a disk image based VM
On the final step of the setup, we get to name our VM and take an option I generally use (and we must use for OVMF), and select to customize the VM before install:

Clicking Finish here brings up a new dialog, where in the overview we need to change our Firmware option from BIOS to UEFI:

If UEFI is not available, your libvirt and virt manager tools may be too old. Note that I'm using the default i440FX machine type, which I recommend for all Windows guests. If you absolutely must use Q35, select it here and complete the VM installation, but you'll later need to edit the XML and use a wrapper script around qemu-kvm to get a proper configuration until libvirt support for Q35 improves. Select Apply and move down to the Processor selection:

Here we can change the number of vCPUs for the guest if we've had second thoughts since our previous selection. We can also change the CPU type exposed to the guest. Often for PCI device assignment and optimal performance we'll want to use host-passthrough here, which is not available in the drop down and needs to by typed manually. This is also our opportunity to change the socket/core configuration for the VM. I'll change my configuration here to expose 4 vCPUs as a single socket, dual-core with threads, so that I can later show vCPU pinning with a thread example. There is pinning configuration available here, but I tend to configure this by editing the XML directly, which I'll show later. We can finish the install before we worry about that.
The next important option for me is the Disk configuration:

As shown here, I've changed my Disk bus from the default to VirtIO. VirtIO is a paravirtualized disk interface, which means that it's designed to be high performance for virtual machines. (EDIT: for further optimization using virtio-scsi rather than virtio-blk, see the comments below) Unfortunately Windows guests do not support VirtIO without additional drivers, so we'll need to configure the VM to provide those drivers during installation. For that, click the Add Hardware button on the bottom left of the screen. Select the Storage and just as we did with the installation media, locate the ISO image for the virtio drivers on your system. The latest virtio drivers can be found here. The dialog should look something like this:

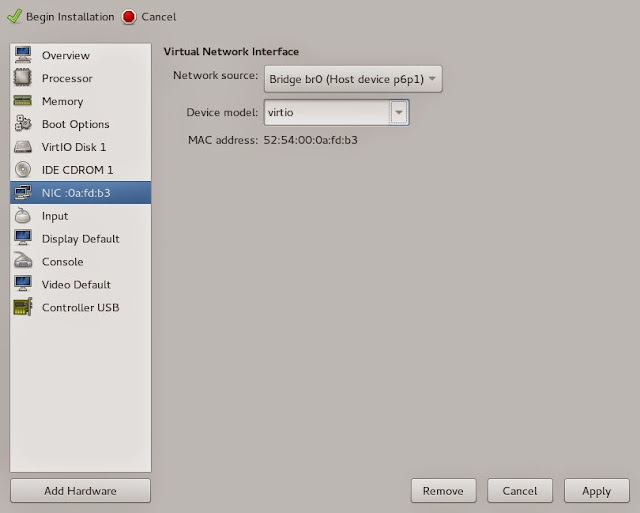
Click Finish to add the CDROM. Since we're adding virtio drivers anyway, let's also optimize our VM NIC by changing it to virtio as well:

The remaining configuration is for your personal preference. If you're using a remote system and do not have ssh authorized keys configured, I'd advise changing the Display to use VNC rather than Spice, otherwise you'll need to enter your password half a dozen times. Select Begin Installation to... begin installation.
In this configuration OVMF will drop to an EFI Shell from which you can navigate to the boot executable:

Type bootx64 and press enter to continue installation and press a key when prompted to boot from the CDROM. I expect this would normally happen automatically if we hadn't added a second CDROM for virtio drivers.
At this point the guest OS installation should proceed normally. When prompted for where to install Windows, select Load Driver, navigate to your CDROM, select Win8, AMD64 (for 64 bit drivers). You'll be given a list of several drivers to choose from. Select all of the drivers using shift-click and click Next. You should now see your disk and can proceed with installation. Generally after installation, the first thing I do is apply at least the recommended updates and reboot the VM.
Before we shutdown to reconfigure, I like to install TightVNC server so I can have remote access even if something goes wrong with the display. I generally do a custom install of TightVNC, disabling client support, and setting security appropriate to the environment. Make note of the IP address of the guest and verify the VNC connection works. Shutdown the VM and we'll trim it down, tune it further, and add a GPU.
Start with the machine details view in virt-manager and remove everything we no longer need. That includes the CDROM devices, the tablet, the display, sound, serial, spice channel, video, virtio serial, and USB redirectors. We can also remove the IDE controller altogether now. That leaves us with a minimal config that looks something like this:

We can also take this opportunity to do a little further tuning by directly editing the XML. On the host, run virsh edit <domain> as root or via sudo. Before the <os> tag, you can optionally add something like the following:
<memoryBacking>
<hugepages/>
</memoryBacking>
<cputune>
<vcpupin vcpu='0' cpuset='2'/>
<vcpupin vcpu='1' cpuset='3'/>
<vcpupin vcpu='2' cpuset='6'/>
<vcpupin vcpu='3' cpuset='7'/>
</cputune>
The <memoryBacking> tag allows us to specify huge pages for the guest. This helps improve the VM efficiency by skipping page table levels when doing address translations. In order for this to work, you must create sufficient huge pages on the host system. Personally I like to do this via kernel commandline by adding something like hugepages=2048 in /etc/sysconfig/grub and regenerating the initramfs as we did in the previous installment of this series. Most processors will only support 2MB hugepages, so by reserving 2048, we're reserving 4096MB worth of memory, which is enough for the 4GB guest I've configured here. Note that transparent huge pages are not effective for VMs making use of device assignment because all of the VM memory needs to be allocated and pinned for the IOMMU before the VM runs. This means the consolidation passes used by transparent huge pages will not be able to combine pages later.
As advertised, we're also configuring CPU pinning. Since I've advertised a single socket, dual-core, threaded processor to my guest, I pin to the same configuration on the host. Processors 2 & 3 on the host are the 2nd and 3rd cores on my quad-core processor and processors 6 & 7 are the threads corresponding to those cores. We can determine this by looking at the "core id" line in /proc/cpuinfo on the host. It generally does not make sense to expose threads to the guest unless it matches the physical host configuration, as we've configured here. Save the XML and if you've chosen to use hugepages remember to reboot the host to make the new commandline take effect or else libvirt will error starting the VM.
I'll start out assigning my Radeon HD8570 to the guest, so we don't yet need to hide any hypervisor features to make things work. Return to virt-manager and select Add Hardware. Select PCI Host Device and find your graphics card GPU function for assignment in the list. Repeat this process for the graphics card audio function. My VM details now look like this:

Start the VM. This time there will not be any console available via virt-manager, the display should initialize and you should see the TianoCore boot splash on the physical monitor connected to the graphics card as well as the Windows startup. Once the guest is booted, you can now reconnect to it using the guest-based VNC server.
At this point we can use the browser to go to amd.com and download driver software for our device. For AMD software it's recommended to specify the driver for your device using the drop down menus on the website rather than allowing the tools to select a driver for you. This holds true for updates via the runtime Catalyst interface later as well. Allowing driver detect often results in blue screens.
At some point during the download, Windows will probably figure out that its hardware changed and switch to it's builtin drivers for the device and the screen resolution will increase. This is a good sign that things are working. Run the Catalyst installation program. I generally use an Express Installation, which hopefully implies that Custom Installations will also work. After installation completes, reboot the VM and you should now have a fully functional, fully graphics accelerated VM.
The GeForce card is nearly as easy, but we first need to work around some of the roadblocks Nvidia has put in place to prevent you from using the hardware you've purchased in the way that you desire (and by my reading conforms to the EULA for their software, but IANAL). For this step we again need to run virsh edit on the VM. Within the <features> section, remove everything between the <hyperv> tags, including the tags themselves. In their place add the following tags:
<kvm>
<hidden state='on'/>
</kvm>
Additionally, within the <clock> tag, find the timer named hypervclock, remove the line containing this tag completely. Save and exit the edit session.
We can now follow the same procedure used in the above Radeon example, add the GPU and audio function to the VM, boot the VM and download drivers from nvidia.com. As with AMD, I typically use the express installation. Restart the VM and you should now have a fully accelerated Nvidia VM.
For either GPU type I highly suggest continuing with following the instructions in my article on configuring the audio device to use Message Signaled Interrupts (MSI) to improve the efficiency and avoid glitchy audio. MSI for the GPU function is typically enabled by default for AMD and not necessarily a performance gain on Nvidia due to an extra trap that Nvidia takes through QEMU to re-enable the MSI via a PCI config write.
Hopefully you now have a working VM with a GPU assigned. If you don't, please comment on what variants of the above setup you'd like to see and I'll work on future articles. I'll re-iterate that the above is my preferred and recommended setup, but VGA-mode assignment with SeaBIOS can also be quite viable provided you're not using Intel IGD graphics for the host (or you're willing to suffer through patching your host kernel for the foreseeable future). Currently on my ToDo list for this series is possibly a UEFI install of Windows 7 (if that's possible), a VGA-mode example by disabling IGD on my host, using host GTX750 and assigning HD8570. That will require a simple qemu-kvm wrapper script to insert the x-vga=on option for vfio-pci. After that I'll likely do a Q35 example with a more complicated wrapper, unless libvirt beats me to adding better native support for Q35. I will not be doing SLI/Crossfire examples as I don't have the hardware for it, there's too much proprietary black magic in SLI, and I really don't see the point of it given the performance of single card solutions today. Stay tuned for future articles and please suggest or up-vote what you'd like to see next.
Hopefully you now have a working VM with a GPU assigned. If you don't, please comment on what variants of the above setup you'd like to see and I'll work on future articles. I'll re-iterate that the above is my preferred and recommended setup, but VGA-mode assignment with SeaBIOS can also be quite viable provided you're not using Intel IGD graphics for the host (or you're willing to suffer through patching your host kernel for the foreseeable future). Currently on my ToDo list for this series is possibly a UEFI install of Windows 7 (if that's possible), a VGA-mode example by disabling IGD on my host, using host GTX750 and assigning HD8570. That will require a simple qemu-kvm wrapper script to insert the x-vga=on option for vfio-pci. After that I'll likely do a Q35 example with a more complicated wrapper, unless libvirt beats me to adding better native support for Q35. I will not be doing SLI/Crossfire examples as I don't have the hardware for it, there's too much proprietary black magic in SLI, and I really don't see the point of it given the performance of single card solutions today. Stay tuned for future articles and please suggest or up-vote what you'd like to see next.
VFIO GPU How To series, part 3 - Host configuration
For my setup I'm using a Fedora 21 system with the virt-preview yum repos to get the latest QEMU and libvirt support along with Gerd Hoffmann's firmware repo for the latest EDK2 OVMF builds. I hope though that the majority of the setup throughout this howto series is mostly distribution agnostic, just make sure you're running a newer distribution with current kernels and tools. Feel free to add comments for other distributions if something is markedly different.
The Vendor:Device IDs for my GPUs and audio functions are therefore 10de:1381, 10de:0fbc, 1002:6611, and 1002:aab0. From this, we can craft a new option to add to our kernel commandline using the same procedure as above for the IOMMU. In this case the commandline addition looks like this:
After adding this to our grub configuration, using grub2-mkconfig, and rebooting, lspci -nnk for these devices should list pci-stub for the kernel driver in use.
A further trick we can use is to craft an ids list using the advanced parsing of PCI vendor and class attributes to create an option list that will claim any Nvidia or AMD GPU or audio device:
If you're using kernel v4.1 or newer, the vfio-pci driver supports the same ids option so you can directly attach devices to vfio-pci and skip pci-stub. vfio-pci is not generally built statically into the kernel, so we need to force it to be loaded early. To do this on Fedora we need to setup the module options we want to use with modprobe.d. I typically use a file named /etc/modprobe.d/local.conf for local, ie. system specific, configuration. In this case, that file would include:
Next we need to ensure that dracut includes the necessary modules to load vfio-pci. I therefore create /etc/dracut.conf.d/local.conf with the following:
(Note, the vfio_virqfd module only exists in kernel v4.1+)
Finally, we need to tell dracut to load vfio-pci first. This is done by once again editing our grub config file and adding the option: rd.driver.pre=vfio-pci Note that in this case we no longer use a pci-stub.ids option from grub, since we're replacing it with vfio-pci. Regenerate the dracut initramfs with dracut -f --kver `uname -r` and reboot to see the effect (The --regenerate-all dracut option is also sometimes useful).
Another issue that users encounter when sequestering devices is what to do when there are multiple devices with the same vendor:device ID and some are intended to be used for the host. Some users have found the xen-pciback module to be a suitable stand-in for pci-stub with the additional feature that the "hide" option for this module takes device addresses rather than device IDs. I can't load this module on Fedora, so here's my solution that I like a bit better.
Create a small script, I've named mine /sbin/vfio-pci-override-vga.sh It contains:
This script will find every non-boot VGA device in the system, use the driver_override feature introduced in kernel v3.16, and make vfio-pci the exclusive driver for that device. If there's a companion audio device at function 1, it also gets a driver override. We then modprobe the vfio-pci module, which will automatically bind to the devices we've specified. Don't forget to make the script executable with chmod 755. Now, in place of the options line in our modprobe.d file, we use the following:
So we specify that to install the vfio-pci module, run the script we just wrote, which sets up our driver overrides and then loads the module, ignoring the install option (-i) to prevent a loop. Finally, we need to tell dracut to include this script in the initramfs, so in addition to the add_drivers+= that we added above, add the following to /etc/dracut.conf.d/local.conf:
Note that the additional utilities required were found using lsinitrd and iteratively added to make the script work. Regenerate the initramfs with dracut again and you should now have all the non-boot VGA devices and their companion audio functions bound to vfio-pci after reboot. The primary graphics should load with the native host driver normally. This method should work for any kernel version, and I think I'm going to switch my setup to use it since I wrote it up here.
Obviously a more simple script can be used to pick specific devices. Here's an example that achieves the same result on my system:
(In this case the find and dirname binaries don't need to be included in the intramfs)
Another couple other bonuses for v4.1 and newer kernels is that by binding devices statically to vfio-pci, they will be placed into a low power state when not in use. Before you get your hopes too high, this generally only saves a few watts and does not stop the fan. v4.1 users with exclusively OVMF guests can also add an "options vfio-pci disable_vga=1" line to their modprobe.d which will cause vfio-pci to opt-out devices from vga arbitration if possible. This prevents VGA arbitration from interfering with host devices, even in configurations like mine with multiple assigned GPUs.
If you're in the unfortunate situation of needing to use legacy VGA BIOS support for your assigned graphics cards and you have Intel host graphics using the i915 driver, this is also the point where you need to patch your host kernel for the i915 VGA arbitration fix. Don't forget that to enable this patch you also need to pass the enable_hd_vgaarb=1 option to the i915 driver. This is typically done via a modprobe.d options entry as discussed above.
At this point your system should be ready to use. The IOMMU is enabled, the IOMMU groups have been verified, the VGA and audio functions for assignment have been bound to either vfio-pci or pci-stub for later use by libvirt, and we've enabled proper VGA arbitration support in the i915 driver if needed. In the next part we'll actually install a VM, and maybe even attach a GPU to it. Stay tuned.
The first thing we need to do on the host is enable the IOMMU. To do this, verify that IOMMU support is enabled in the host BIOS. How to do this will be specific to your hardware/BIOS vendor. If you can't find an option, don't fret, it may be tied to processor virtualization support. If you're using an Intel processor, check http://ark.intel.com to verify that your processor supports VT-d before going any further.
Next we need to modify the kernel commandline to allow the kernel to enable IOMMU support. This will be similar between distributions, but not identical. On Fedora we need to edit /etc/sysconfig/grub. Find the GRUB_CMDLINE_LINUX line and within the quotes add either intel_iommu=on or amd_iommu=on, depending on whether your platform is Intel or AMD. You may also want to add the option iommu=pt, which sets the IOMMU into passthrough mode for host devices. This reduces the overhead of the IOMMU for host owned devices, but also removes any protection the IOMMU may have provided again errant DMA from devices. If you weren't using the IOMMU before, there's nothing lost. Regardless of passthrough mode, the IOMMU will provide the same degree of isolation for assigned devices.
Save the system grub configuration file and use your distribution provided update scrips to apply this configuration to the boot-time grub config file. On Fedora, the command is:
# grub2-mkconfig -o /etc/grub2.cfg
If your host system boots via UEFI, the correct target file is /etc/grub2-efi.cfg.
With these changes, reboot the system and verify that the IOMMU is enabled. To do this, first verify that the kernel booted with the desired updates to the commandline. We can check this using:
# cat /proc/cmdline
If the changes are not there, verify that you've booted the correct kernel or double check instructions specific to your distribution. If they are there, then we next need to check that the IOMMU is actually functional. The easiest way to do this is to check for IOMMU groups, which are setup by the IOMMU and will be used by VFIO for assignment. To do this, run the following:
# find /sys/kernel/iommu_groups/ -type l
/sys/kernel/iommu_groups/0/devices/0000:00:00.0
/sys/kernel/iommu_groups/1/devices/0000:00:01.0
/sys/kernel/iommu_groups/1/devices/0000:01:00.0
/sys/kernel/iommu_groups/1/devices/0000:01:00.1
/sys/kernel/iommu_groups/2/devices/0000:00:02.0
/sys/kernel/iommu_groups/3/devices/0000:00:16.0
/sys/kernel/iommu_groups/4/devices/0000:00:1a.0
/sys/kernel/iommu_groups/5/devices/0000:00:1b.0
/sys/kernel/iommu_groups/6/devices/0000:00:1c.0
/sys/kernel/iommu_groups/7/devices/0000:00:1c.5
/sys/kernel/iommu_groups/8/devices/0000:00:1c.6
/sys/kernel/iommu_groups/9/devices/0000:00:1c.7
/sys/kernel/iommu_groups/9/devices/0000:05:00.0
/sys/kernel/iommu_groups/10/devices/0000:00:1d.0
/sys/kernel/iommu_groups/11/devices/0000:00:1f.0
/sys/kernel/iommu_groups/11/devices/0000:00:1f.2
/sys/kernel/iommu_groups/11/devices/0000:00:1f.3
/sys/kernel/iommu_groups/12/devices/0000:02:00.0
/sys/kernel/iommu_groups/12/devices/0000:02:00.1
/sys/kernel/iommu_groups/13/devices/0000:03:00.0
/sys/kernel/iommu_groups/14/devices/0000:04:00.0
If you get output like above, then the IOMMU is working. If you do not get a list of devices, then something is wrong with the IOMMU configuration on your system, either not properly enabled or not supported by the hardware and you'll need to figure out the problem before moving forward.
This is also a good time to verify that we have the desired isolation via the IOMMU groups. In the above example, there's a separate group per device except for the following groups: 1, 9, 11, and 12. Group 1 includes:
This is also a good time to verify that we have the desired isolation via the IOMMU groups. In the above example, there's a separate group per device except for the following groups: 1, 9, 11, and 12. Group 1 includes:
00:01.0 PCI bridge: Intel Corporation Xeon E3-1200 v2/3rd Gen Core processor PCI Express Root Port (rev 09)
01:00.0 VGA compatible controller: NVIDIA Corporation GM107 [GeForce GTX 750] (rev a2)
01:00.1 Audio device: NVIDIA Corporation Device 0fbc (rev a1)
This includes the processor root port and my GeForce card. This is a case where the processor root port does not provide isolation and is therefore included in the IOMMU group. The host driver for the root port should remain in place, with only the two endpoint devices, the GPU itself and its companion audio function bound to vfio-pci.
Group 9 has a similar constraint, though in this case device 0000:00:1c.7 is not a root port, but a PCI bridge. Since this is conventional PCI, the bridge and all of the devices behind it are grouped together. Device 0000:05:00.0 is another bridge, so there's nothing assignable in the IOMMU group anyway.
Group 11 is composed of internal components, an ISA bridge, SATA controller, and SMBus device. These are grouped because there's not ACS between the devices and therefore no isolation. I don't plan to assign any of these devices anyway, so it's not an issue.
Group 12 includes only the functions of my second graphics card, so the grouping here is also reasonable and perfectly usable for our purposes.
If your grouping is not reasonable, or usable, you may be able to "fix" this by using the ACS override patch, but carefully consider the implications of doing this. There is a potential for putting your data at risk. Read my IOMMU groups article again to make sure you understand the issue.
Next we need to handle the problem that we only intend to use the discrete GPUs for guests, we do not want host drivers attaching to them. This avoids issues with the host driver unbinding and re-binding to the device. Generally this is only necessary for graphics cards, though I also throw in the companion audio function to keep the host desktop from getting confused which audio device to use. We have a couple options for doing this. The most common option is to use the pci-stub driver to claim these devices before native host drivers have the opportunity. Fedora builds the pci-stub driver statically into the kernel, giving it loading priority over any loadable modules, simplifying this even further. If your distro doesn't keep reading, we'll cover a similar scenario with vfio-pci.
The first step is to determine the PCI vendor and device IDs we need to bind to pci-stub. For this we use lspci:
If your grouping is not reasonable, or usable, you may be able to "fix" this by using the ACS override patch, but carefully consider the implications of doing this. There is a potential for putting your data at risk. Read my IOMMU groups article again to make sure you understand the issue.
Next we need to handle the problem that we only intend to use the discrete GPUs for guests, we do not want host drivers attaching to them. This avoids issues with the host driver unbinding and re-binding to the device. Generally this is only necessary for graphics cards, though I also throw in the companion audio function to keep the host desktop from getting confused which audio device to use. We have a couple options for doing this. The most common option is to use the pci-stub driver to claim these devices before native host drivers have the opportunity. Fedora builds the pci-stub driver statically into the kernel, giving it loading priority over any loadable modules, simplifying this even further. If your distro doesn't keep reading, we'll cover a similar scenario with vfio-pci.
The first step is to determine the PCI vendor and device IDs we need to bind to pci-stub. For this we use lspci:
$ lspci -n -s 1:
01:00.0 0300: 10de:1381 (rev a2)
01:00.1 0403: 10de:0fbc (rev a1)
$ lspci -n -s 2:
02:00.0 0300: 1002:6611
02:00.1 0403: 1002:aab0
The Vendor:Device IDs for my GPUs and audio functions are therefore 10de:1381, 10de:0fbc, 1002:6611, and 1002:aab0. From this, we can craft a new option to add to our kernel commandline using the same procedure as above for the IOMMU. In this case the commandline addition looks like this:
pci-stub.ids=10de:1381,10de:0fbc,1002:6611,1002:aab0
After adding this to our grub configuration, using grub2-mkconfig, and rebooting, lspci -nnk for these devices should list pci-stub for the kernel driver in use.
A further trick we can use is to craft an ids list using the advanced parsing of PCI vendor and class attributes to create an option list that will claim any Nvidia or AMD GPU or audio device:
pci-stub.ids=1002:ffffffff:ffffffff:ffffffff:00030000:ffff00ff,1002:ffffffff:ffffffff:ffffffff:00040300:ffffffff,10de:ffffffff:ffffffff:ffffffff:00030000:ffff00ff,10de:ffffffff:ffffffff:ffffffff:00040300:ffffffff
If you're using kernel v4.1 or newer, the vfio-pci driver supports the same ids option so you can directly attach devices to vfio-pci and skip pci-stub. vfio-pci is not generally built statically into the kernel, so we need to force it to be loaded early. To do this on Fedora we need to setup the module options we want to use with modprobe.d. I typically use a file named /etc/modprobe.d/local.conf for local, ie. system specific, configuration. In this case, that file would include:
options vfio-pci ids=1002:ffffffff:ffffffff:ffffffff:00030000:ffff00ff,1002:ffffffff:ffffffff:ffffffff:00040300:ffffffff,10de:ffffffff:ffffffff:ffffffff:00030000:ffff00ff,10de:ffffffff:ffffffff:ffffffff:00040300:ffffffff
Next we need to ensure that dracut includes the necessary modules to load vfio-pci. I therefore create /etc/dracut.conf.d/local.conf with the following:
add_drivers+="vfio vfio_iommu_type1 vfio_pci vfio_virqfd"
(Note, the vfio_virqfd module only exists in kernel v4.1+)
Finally, we need to tell dracut to load vfio-pci first. This is done by once again editing our grub config file and adding the option: rd.driver.pre=vfio-pci Note that in this case we no longer use a pci-stub.ids option from grub, since we're replacing it with vfio-pci. Regenerate the dracut initramfs with dracut -f --kver `uname -r` and reboot to see the effect (The --regenerate-all dracut option is also sometimes useful).
Another issue that users encounter when sequestering devices is what to do when there are multiple devices with the same vendor:device ID and some are intended to be used for the host. Some users have found the xen-pciback module to be a suitable stand-in for pci-stub with the additional feature that the "hide" option for this module takes device addresses rather than device IDs. I can't load this module on Fedora, so here's my solution that I like a bit better.
Create a small script, I've named mine /sbin/vfio-pci-override-vga.sh It contains:
#!/bin/sh
for i in $(find /sys/devices/pci* -name boot_vga); do
if [ $(cat $i) -eq 0 ]; then
GPU=$(dirname $i)
AUDIO=$(echo $GPU | sed -e "s/0$/1/")
echo "vfio-pci" > $GPU/driver_override
if [ -d $AUDIO ]; then
echo "vfio-pci" > $AUDIO/driver_override
fi
fi
done
modprobe -i vfio-pci
This script will find every non-boot VGA device in the system, use the driver_override feature introduced in kernel v3.16, and make vfio-pci the exclusive driver for that device. If there's a companion audio device at function 1, it also gets a driver override. We then modprobe the vfio-pci module, which will automatically bind to the devices we've specified. Don't forget to make the script executable with chmod 755. Now, in place of the options line in our modprobe.d file, we use the following:
install vfio-pci /sbin/vfio-pci-override-vga.sh
So we specify that to install the vfio-pci module, run the script we just wrote, which sets up our driver overrides and then loads the module, ignoring the install option (-i) to prevent a loop. Finally, we need to tell dracut to include this script in the initramfs, so in addition to the add_drivers+= that we added above, add the following to /etc/dracut.conf.d/local.conf:
install_items+="/sbin/vfio-pci-override-vga.sh /usr/bin/find /usr/bin/dirname"
Note that the additional utilities required were found using lsinitrd and iteratively added to make the script work. Regenerate the initramfs with dracut again and you should now have all the non-boot VGA devices and their companion audio functions bound to vfio-pci after reboot. The primary graphics should load with the native host driver normally. This method should work for any kernel version, and I think I'm going to switch my setup to use it since I wrote it up here.
Obviously a more simple script can be used to pick specific devices. Here's an example that achieves the same result on my system:
#!/bin/sh
DEVS="0000:01:00.0 0000:01:00.1 0000:02:00.0 0000:02:00.1"
for DEV in $DEVS; do
echo "vfio-pci" > /sys/bus/pci/devices/$DEV/driver_override
done
modprobe -i vfio-pci
(In this case the find and dirname binaries don't need to be included in the intramfs)
Another couple other bonuses for v4.1 and newer kernels is that by binding devices statically to vfio-pci, they will be placed into a low power state when not in use. Before you get your hopes too high, this generally only saves a few watts and does not stop the fan. v4.1 users with exclusively OVMF guests can also add an "options vfio-pci disable_vga=1" line to their modprobe.d which will cause vfio-pci to opt-out devices from vga arbitration if possible. This prevents VGA arbitration from interfering with host devices, even in configurations like mine with multiple assigned GPUs.
If you're in the unfortunate situation of needing to use legacy VGA BIOS support for your assigned graphics cards and you have Intel host graphics using the i915 driver, this is also the point where you need to patch your host kernel for the i915 VGA arbitration fix. Don't forget that to enable this patch you also need to pass the enable_hd_vgaarb=1 option to the i915 driver. This is typically done via a modprobe.d options entry as discussed above.
At this point your system should be ready to use. The IOMMU is enabled, the IOMMU groups have been verified, the VGA and audio functions for assignment have been bound to either vfio-pci or pci-stub for later use by libvirt, and we've enabled proper VGA arbitration support in the i915 driver if needed. In the next part we'll actually install a VM, and maybe even attach a GPU to it. Stay tuned.
VFIO GPU How To series, part 2 - Expectations
From part 1 we learned some basic guidelines for the hardware necessary to support GPU assignment, but let's take a moment to talk about what we're actually trying to accomplish. There's no point in proceeding further if the solution doesn't meet your goals and expectations.
First things first, PCI device assignment is a means to exclusively assign a device to a VM. Devices cannot be shared among multiple guests and cannot be shared between host and guest. The solution we're discussing here is not vGPU, VGX, or any other means of multiplexing a single GPU among multiple users. Furthermore, VFIO works on an isolation unit known as an IOMMU Group. Endpoints within an IOMMU group follow the same rule; they're either owned by a single guest or the host, not both. As referenced in part 1, a previous article on IOMMU groups attempts to explain this relationship.
Next, be aware that Linux graphics drivers, both open source and proprietary are rather poor at dynamically binding and unbinding devices. This means that hot-unplugging a graphics adapter from the host configuration, assigning it to a guest for some task, and then re-plugging it back to the host desktop is not really achievable just yet. This is something that could happen, but graphics drivers need to get to the same level of robustness around binding and unbinding devices as NIC drivers before this is really practical.
Probably the primary incorrect expectations that users have around GPU assignment is the idea that the out-of-band VM graphics display, via Spice or VNC, will still be available, it will somehow just be accelerated with an assigned GPU. The misconception is reinforced by youtube videos that show accelerated graphics running within a window on the host system. In both of these examples, the remote display is actually accomplished using TightVNC running within the guest. Don't get me wrong, TightVNC is a great solution for some use cases, and local software bridges for virtio networking provide extreme amounts of bandwidth to make this a bit more practical than going across a physical wire, but it's not a full replacement for a console screen within virt-manager or other VM management tools. TightVNC is a server running within the guest, it's only available once the guest is booted, it's rather CPU intensive in the guest, and it's only moderately ok for the remote display of 3D graphics. When using GPU assignment, the only fully accelerated guest output is through the monitor connector to the physical graphics card itself. We currently have no ability to scrape the framebuffer from the physical device, driven by proprietary drivers, and feed those images into the QEMU remote graphics protocols. There are commercial solutions to this problem, NICE DCV and HP RGS are both software solutions to provide better remote 3D capabilities. It's even possible to co-assign PCoIP cards to the VM to achieve high performance remote 3D. In my use case, I enable TightVNC for 2D interaction with the VM and use the local monitor or software stacks like Steam in home streaming for remote use of the VM. Tools like Synergy are useful for local monitors to seamlessly combine mouse and keyboard for multiple desktops.
Another frequent misconception is that integrated graphics devices, like Intel IGD graphics, are just another graphics device and should work with GPU assignment. Unfortunately IGD is not only non-discrete from the aspect of being integrated into the processor, but it's also non-discrete in that the drivers for IGD depend on various registers and operations regions and firmware tables spread across the chipset. Thus, while we can attach the IGD GPU to the guest, it doesn't work due to driver requirements. This issue is being worked and will hopefully have a solution in the near future. As I understand it, AMD APUs are much more similar to their discrete counterparts, but the device topology still makes them difficult to work with. We rely fairly heavily on PCI bus resets in order to put GPUs into a clean state for the guest and between guest reboots, but this is not possible on IGD or APUs because they reside on the host PCIe root complex. Resetting the host bus is not only non-standard, but it would reset every PCI device in the system. We really need Function Level Reset (FLR) support in the device to make this work. For now, IGD assignment doesn't work, and I have no experience with APU assignment, but expect it to work poorly due to lack of reset.
Ok, I think that tackles the top misconceptions regarding GPU assignment. Hopefully there are still plenty of interesting use cases for your application. In the next part we'll start to configure our host system for device assignment. Stay tuned.
Another frequent misconception is that integrated graphics devices, like Intel IGD graphics, are just another graphics device and should work with GPU assignment. Unfortunately IGD is not only non-discrete from the aspect of being integrated into the processor, but it's also non-discrete in that the drivers for IGD depend on various registers and operations regions and firmware tables spread across the chipset. Thus, while we can attach the IGD GPU to the guest, it doesn't work due to driver requirements. This issue is being worked and will hopefully have a solution in the near future. As I understand it, AMD APUs are much more similar to their discrete counterparts, but the device topology still makes them difficult to work with. We rely fairly heavily on PCI bus resets in order to put GPUs into a clean state for the guest and between guest reboots, but this is not possible on IGD or APUs because they reside on the host PCIe root complex. Resetting the host bus is not only non-standard, but it would reset every PCI device in the system. We really need Function Level Reset (FLR) support in the device to make this work. For now, IGD assignment doesn't work, and I have no experience with APU assignment, but expect it to work poorly due to lack of reset.
Ok, I think that tackles the top misconceptions regarding GPU assignment. Hopefully there are still plenty of interesting use cases for your application. In the next part we'll start to configure our host system for device assignment. Stay tuned.
VFIO GPU How To series, part 1 - The hardware
This is an attempt to make a definitive howto guide for GPU assignment with QEMU/KVM and VFIO. It should also be relevant for general PCI device assignment with VFIO. For part 1 I'll simply cover the hardware that I use, it's features and drawbacks for this application and what I might do differently in designing a system specifically for GPU assignment. In later parts we'll get in to installing VMs and configuring GPU assignment.

My IOMMU groups look like this:
Note that even though I only have a single PCH root port slot, there are multiple internal root ports connecting the built-in I/O, including the USB 3.0 controller and Ethernet. Without native ACS support or the ACS quirk for these PCH root ports, all of the 1c.* root ports and devices behind them would be grouped together.
Let's move on to the graphics cards. This is an always-on desktop system, so noise and power (and having representative devices) are more important to me than ultimate performance. The cards I'm using are therefore an EVGA GTX 750 Superclocked:


The GTX750 is based on Maxwell, giving it an excellent power-performance ratio and the 8570 is based on Oland, making it one of the newer generation of GCN chips from AMD. The 8570 is by no means a performance card, but I don't have room for a double-wide graphics card in my PCH root port slot and it's only running x4 electrically anyway. OEM cards seem to be a good way to find cheap cards on ebay, but their cooling solutions leave something to be desired. I actually replace the heatsink fan on the 8570 with a Cooler Master CoolViva Z1. I'll also mention that before upgrading to the GTX750 I successfully ran a GT 635 OEM, which is fairly comparable in specs and price to the 8570.
This system was not designed or purchased with this particular use case in mind. In fact, it only gained VT-d capabilities after upgrading from the Core i3 processor that I originally had installed. So what would an ideal system be for this purpose? First, IOMMU support via Intel VT-d or AMD-Vi is required. This is not negotiable. If we stay with Intel Core i5/i7 (no VT-d support in i3) or Xeon E3-12xx series processors then we need to be well aware of the lack of ACS support on processor root ports. In an application like above, I'm more limited by physical slots so this is not a problem. If I wanted more processor-based root port slots, the trade-off in using these processors is the lack of isolation. The ACS override patch will not go upstream and is not recommended for downstreams or users due to the potential risk in assuming isolation where none may exist. The alternative is to set our sights on Xeon E5 or higher processors. This is potentially a higher price point, but I see plenty of users spending many hundreds of dollars on high-end graphics cards, yet skimping on the processor and complaining about needing to patch their kernel. Personally I'd rather put more towards the platform to avoid that hassle.
There are also users that prefer AMD platforms. Personally I don't find them that compelling. The latest non-APU chipset is several years old and the processors are too power hungry for my taste. A-series processors aren't much better and their chipsets are largely unknown with respect to both isolation and IOMMU support. Besides the processor and chipset technologies, Intel has a huge advantage with http://ark.intel.com/ in being able to quickly and easily research the capabilities of a given product.
But what about the graphics cards? If you're looking for a solution supported by the graphics card vendor, you're limited to Nvidia Quadro K-series, model 2000 or better (or GRID or Tesla, but those are not terribly relevant in this context). Nvidia supports running these cards in QEMU/KVM virtual environments using VFIO in a secondary display configuration. In other words, pre-boot (BIOS), OS boot, and initial installation and maintenance is done using an emulated graphics device and the GPU is only activated once the proprietary graphics drivers are enabled in the guest. This mode of operation does not depend on the graphics ROM (legacy vs UEFI) and works with current Windows and Linux guests.
When choosing between GeForce and Radeon, there's no clear advantage of one versus the other that's necessarily sufficient to trump personal preference. AMD cards are known to experience occasional blue screens for Windows guests and a couple of the more recent GPUs have known reset issues. On the other hand, evidence suggests that Nvidia may be actively trying to subvert VM usage of GeForce graphics cards. As noted in the FAQ we need to both hide KVM as the hypervisor as well as disable KVM's support for Microsoft Hyper-V extensions in order for Nvidia's driver to work in the VM. The statement from Nvidia has always been that they are not intentionally trying to block this use, but that it's not supported and won't be fixed. Personally, that's a hard explanation to swallow.
My observation is that AMD appears more interested in supporting VM use cases, but they're not doing anything in particular to enable it or make it work better. Nvidia generally works better, but each new driver upgrade is an opportunity for Nvidia to introduce new barriers or shut down this usage model entirely. If Nvidia were to make a gesture of support by fixing the current "bugs" in hypervisor detection, the choice would be clear IMHO.
Users also often like to assign additional hardware to VMs to make them feel more like separate systems. In my use case, I can run multiple guests simultaneously and have a monitor for each graphics cards, but they are only used by a single user, me. I'm therefore perfectly happy using Synergy to share my mouse and keyboard and virtio disk and network for the VMs works well. For an actual multi-seat use case, being able to connect an individual mouse and keyboard per seat is obviously useful. USB "passthrough", which is different from "assignment", works on individual USB endpoints and is one solution to this problem, but generally doesn't work well with hotplug (in my experience). Using multiple USB host controllers, with a host controller assigned per VM is another option for providing a more native solution. This however means that we start increasing our slot requirements and therefore our concerns about isolation between those slots.
Assigning physical NICs to a system is also an option, though for a desktop setup it's generally unnecessary. In the 1Gbps realm, virtio can easily handle the bandwidth, so the advantage of assignment is lower latency and more aggregate throughput among VMs and host. If 10Gbps is a concern, assignment becomes more practical. If you do decide to assign NICs, I find Intel NICs to be a good choice for assignment.
I generally discourage users from assigning disk controllers directly to a VM. Often the builtin controllers store their boot ROM in the system firmware, making it difficult to actually boot the guest from an assigned HBA. Beyond that, the additional latency imposed by a paravirtual disk controller is typically substantially less than the latency of the disk itself, so the return on investment and additional complication of an assigned storage controller is generally not worthwhile for average configurations.
Audio is also sometimes an issue for users. In my configuration I use HDMI audio from the graphics card for both VMs. This works well, so long as we make sure the guest is using MSI interrupts for the audio devices. Other users prefer USB audio devices, often in a passthrough configuration. Connecting separate VMs to the host user's pulse-audio session is generally difficult, but not impossible. A contributing problem to this is that assigned devices, such as the graphics card, need to be used in libvirt's "system" mode, while connecting to the user's pulseaudio daemon would probably be easier in a libvirt user session.
Finally, number of processor cores and total memory size plays an important factor for the guests you'll eventually be running. When using PCI device assignment, VM memory cannot be over-committed. The assigned device is capable of DMA through the IOMMU, which means that all of guest memory needs to not only be allocated in advanced, but pinned into memory to make the guest physical to host physical mappings static for the VM. Total memory therefore needs to accommodate all assigned device VMs that might be run simultaneously, plus memory for whatever other applications the host is running. vCPUs can be over-committed, regardless of an assigned device, but doing so breaks down some of the performance isolation we gain by device assignment. If a "native" feel is desired, we'll want enough cores that we don't need to share between VMs and a few left over for applications and overhead on the host.
Hopefully that helps give you an idea of where to start with choosing hardware. In the next segment we'll cover what to expect in a GPU assignment VM as users often have misconceptions around where the display is output and how to interact with the VM.
The system I'm using is nothing particularly new or exciting, it's simply a desktop based on an Asus P8H67-M PRO/CSM:
I'm using a Xeon E3-1245 v2, Ivy Bridge processor. I wouldn't necessarily recommend this particular setup (it's probably only available on ebay anymore anyway), but I'll point out a few interesting points about it to help you pick your own system. First, the motherboard uses an H67 chipset, which is covered by the Intel PCH ACS quirk. This means that devices connected via the PCH root ports will be isolated from each other. That includes anything plugged into the black PCIe 2.0 x16 (electrically x4) slot shown on the top of the picture above, as well as builtin devices hanging off the PCH root ports internally. The blue x16 slot is the higher performance PCIe 3.0 (3.0 for my processor) slot driven from the processor root ports. The motherboard manual will sometimes have block diagrams indicating which ports are derived from which component, this particular board doesn't.
A convenient "feature" of this board is that there's only a single processor-based root port slot. That's not exactly a feature, but processors for this socket (1155) that also support Intel VT-d include Core i5, i7, and Xeon E3-1200 series. None of these processors support PCIe ACS between the root ports (see here for why that's important), this means multiple root ports would not be isolated from each other. If I had more than one processor-based root ports and made use of them, I might need the ACS override patch to fake isolation that may or may not exist.
There are also a couple conventional PCI slots on this board that are largely useless. Not only because conventional PCI is not a good choice for device assignment, and not only because they're blocked by graphics card heatsinks, but because they're driven by an ASMedia ASM1083 (rev 1) PCIe-to-PCI bridge, which has all sorts of interrupt issues, even on bare metal. This spawns my personal dislike and distrust for anything made by ASMedia.
The onboard NIC is a Realtek RTL8111, which is not particularly interesting either. Realtek NICs are also a poor choice for doing direct device assignment to a guest; they do strange and non-standard things. On my system, I use it with a software bridge and virtio network devices for the VMs. This provides plenty of performance for my use cases (including Steam in-home streaming) as well as local connectivity for Synergy.
The onboard NIC is a Realtek RTL8111, which is not particularly interesting either. Realtek NICs are also a poor choice for doing direct device assignment to a guest; they do strange and non-standard things. On my system, I use it with a software bridge and virtio network devices for the VMs. This provides plenty of performance for my use cases (including Steam in-home streaming) as well as local connectivity for Synergy.
Final note on the base platform, I'm using the processor integrated Intel HD Graphics P4600 for the host graphics. This particular motherboard only allows BIOS selection between IGD, PCIe, and PCI for the primary graphics devices. There is no way to specify a particular PCIe slot for primary graphics as other vendors, like Gigabyte, tend to provide. This motherboard is therefore not a good choice for discrete host graphics since we only have one fixed configuration for selecting the primary graphics device between plugin cards.
For reference, lspci on this system:
-[0000:00]-+-00.0 Intel Corporation Xeon E3-1200 v2/Ivy Bridge DRAM Controller
+-01.0-[01]--+-00.0 NVIDIA Corporation GM107 [GeForce GTX 750]
| \-00.1 NVIDIA Corporation Device 0fbc
+-02.0 Intel Corporation Xeon E3-1200 v2/3rd Gen Core processor Graphics Controller
+-16.0 Intel Corporation 6 Series/C200 Series Chipset Family MEI Controller #1
+-1a.0 Intel Corporation 6 Series/C200 Series Chipset Family USB Enhanced Host Controller #2
+-1b.0 Intel Corporation 6 Series/C200 Series Chipset Family High Definition Audio Controller
+-1c.0-[02]--+-00.0 Advanced Micro Devices, Inc. [AMD/ATI] Oland [Radeon HD 8570 / R7 240 OEM]
| \-00.1 Advanced Micro Devices, Inc. [AMD/ATI] Cape Verde/Pitcairn HDMI Audio [Radeon HD 7700/7800 Series]
+-1c.5-[03]----00.0 ASMedia Technology Inc. ASM1042 SuperSpeed USB Host Controller
+-1c.6-[04]----00.0 Realtek Semiconductor Co., Ltd. RTL8111/8168/8411 PCI Express Gigabit Ethernet Controller
+-1c.7-[05-06]----00.0-[06]--
+-1d.0 Intel Corporation 6 Series/C200 Series Chipset Family USB Enhanced Host Controller #1
+-1f.0 Intel Corporation H67 Express Chipset Family LPC Controller
+-1f.2 Intel Corporation 6 Series/C200 Series Chipset Family SATA AHCI Controller
\-1f.3 Intel Corporation 6 Series/C200 Series Chipset Family SMBus Controller
My IOMMU groups look like this:
/sys/kernel/iommu_groups/0/devices/0000:00:00.0
/sys/kernel/iommu_groups/1/devices/0000:00:01.0
/sys/kernel/iommu_groups/1/devices/0000:01:00.0
/sys/kernel/iommu_groups/1/devices/0000:01:00.1
/sys/kernel/iommu_groups/2/devices/0000:00:02.0
/sys/kernel/iommu_groups/3/devices/0000:00:16.0
/sys/kernel/iommu_groups/4/devices/0000:00:1a.0
/sys/kernel/iommu_groups/5/devices/0000:00:1b.0
/sys/kernel/iommu_groups/6/devices/0000:00:1c.0
/sys/kernel/iommu_groups/7/devices/0000:00:1c.5
/sys/kernel/iommu_groups/8/devices/0000:00:1c.6
/sys/kernel/iommu_groups/9/devices/0000:00:1c.7
/sys/kernel/iommu_groups/9/devices/0000:05:00.0
/sys/kernel/iommu_groups/10/devices/0000:00:1d.0
/sys/kernel/iommu_groups/11/devices/0000:00:1f.0
/sys/kernel/iommu_groups/11/devices/0000:00:1f.2
/sys/kernel/iommu_groups/11/devices/0000:00:1f.3
/sys/kernel/iommu_groups/12/devices/0000:02:00.0
/sys/kernel/iommu_groups/12/devices/0000:02:00.1
/sys/kernel/iommu_groups/13/devices/0000:03:00.0
/sys/kernel/iommu_groups/14/devices/0000:04:00.0
Note that even though I only have a single PCH root port slot, there are multiple internal root ports connecting the built-in I/O, including the USB 3.0 controller and Ethernet. Without native ACS support or the ACS quirk for these PCH root ports, all of the 1c.* root ports and devices behind them would be grouped together.
Let's move on to the graphics cards. This is an always-on desktop system, so noise and power (and having representative devices) are more important to me than ultimate performance. The cards I'm using are therefore an EVGA GTX 750 Superclocked:
And an AMD HD 8570 OEM:
This system was not designed or purchased with this particular use case in mind. In fact, it only gained VT-d capabilities after upgrading from the Core i3 processor that I originally had installed. So what would an ideal system be for this purpose? First, IOMMU support via Intel VT-d or AMD-Vi is required. This is not negotiable. If we stay with Intel Core i5/i7 (no VT-d support in i3) or Xeon E3-12xx series processors then we need to be well aware of the lack of ACS support on processor root ports. In an application like above, I'm more limited by physical slots so this is not a problem. If I wanted more processor-based root port slots, the trade-off in using these processors is the lack of isolation. The ACS override patch will not go upstream and is not recommended for downstreams or users due to the potential risk in assuming isolation where none may exist. The alternative is to set our sights on Xeon E5 or higher processors. This is potentially a higher price point, but I see plenty of users spending many hundreds of dollars on high-end graphics cards, yet skimping on the processor and complaining about needing to patch their kernel. Personally I'd rather put more towards the platform to avoid that hassle.
There are also users that prefer AMD platforms. Personally I don't find them that compelling. The latest non-APU chipset is several years old and the processors are too power hungry for my taste. A-series processors aren't much better and their chipsets are largely unknown with respect to both isolation and IOMMU support. Besides the processor and chipset technologies, Intel has a huge advantage with http://ark.intel.com/ in being able to quickly and easily research the capabilities of a given product.
But what about the graphics cards? If you're looking for a solution supported by the graphics card vendor, you're limited to Nvidia Quadro K-series, model 2000 or better (or GRID or Tesla, but those are not terribly relevant in this context). Nvidia supports running these cards in QEMU/KVM virtual environments using VFIO in a secondary display configuration. In other words, pre-boot (BIOS), OS boot, and initial installation and maintenance is done using an emulated graphics device and the GPU is only activated once the proprietary graphics drivers are enabled in the guest. This mode of operation does not depend on the graphics ROM (legacy vs UEFI) and works with current Windows and Linux guests.
When choosing between GeForce and Radeon, there's no clear advantage of one versus the other that's necessarily sufficient to trump personal preference. AMD cards are known to experience occasional blue screens for Windows guests and a couple of the more recent GPUs have known reset issues. On the other hand, evidence suggests that Nvidia may be actively trying to subvert VM usage of GeForce graphics cards. As noted in the FAQ we need to both hide KVM as the hypervisor as well as disable KVM's support for Microsoft Hyper-V extensions in order for Nvidia's driver to work in the VM. The statement from Nvidia has always been that they are not intentionally trying to block this use, but that it's not supported and won't be fixed. Personally, that's a hard explanation to swallow.
My observation is that AMD appears more interested in supporting VM use cases, but they're not doing anything in particular to enable it or make it work better. Nvidia generally works better, but each new driver upgrade is an opportunity for Nvidia to introduce new barriers or shut down this usage model entirely. If Nvidia were to make a gesture of support by fixing the current "bugs" in hypervisor detection, the choice would be clear IMHO.
Users also often like to assign additional hardware to VMs to make them feel more like separate systems. In my use case, I can run multiple guests simultaneously and have a monitor for each graphics cards, but they are only used by a single user, me. I'm therefore perfectly happy using Synergy to share my mouse and keyboard and virtio disk and network for the VMs works well. For an actual multi-seat use case, being able to connect an individual mouse and keyboard per seat is obviously useful. USB "passthrough", which is different from "assignment", works on individual USB endpoints and is one solution to this problem, but generally doesn't work well with hotplug (in my experience). Using multiple USB host controllers, with a host controller assigned per VM is another option for providing a more native solution. This however means that we start increasing our slot requirements and therefore our concerns about isolation between those slots.
Assigning physical NICs to a system is also an option, though for a desktop setup it's generally unnecessary. In the 1Gbps realm, virtio can easily handle the bandwidth, so the advantage of assignment is lower latency and more aggregate throughput among VMs and host. If 10Gbps is a concern, assignment becomes more practical. If you do decide to assign NICs, I find Intel NICs to be a good choice for assignment.
I generally discourage users from assigning disk controllers directly to a VM. Often the builtin controllers store their boot ROM in the system firmware, making it difficult to actually boot the guest from an assigned HBA. Beyond that, the additional latency imposed by a paravirtual disk controller is typically substantially less than the latency of the disk itself, so the return on investment and additional complication of an assigned storage controller is generally not worthwhile for average configurations.
Audio is also sometimes an issue for users. In my configuration I use HDMI audio from the graphics card for both VMs. This works well, so long as we make sure the guest is using MSI interrupts for the audio devices. Other users prefer USB audio devices, often in a passthrough configuration. Connecting separate VMs to the host user's pulse-audio session is generally difficult, but not impossible. A contributing problem to this is that assigned devices, such as the graphics card, need to be used in libvirt's "system" mode, while connecting to the user's pulseaudio daemon would probably be easier in a libvirt user session.
Finally, number of processor cores and total memory size plays an important factor for the guests you'll eventually be running. When using PCI device assignment, VM memory cannot be over-committed. The assigned device is capable of DMA through the IOMMU, which means that all of guest memory needs to not only be allocated in advanced, but pinned into memory to make the guest physical to host physical mappings static for the VM. Total memory therefore needs to accommodate all assigned device VMs that might be run simultaneously, plus memory for whatever other applications the host is running. vCPUs can be over-committed, regardless of an assigned device, but doing so breaks down some of the performance isolation we gain by device assignment. If a "native" feel is desired, we'll want enough cores that we don't need to share between VMs and a few left over for applications and overhead on the host.
Hopefully that helps give you an idea of where to start with choosing hardware. In the next segment we'll cover what to expect in a GPU assignment VM as users often have misconceptions around where the display is output and how to interact with the VM.
Subscribe to:
Posts (Atom)